PROFESJONALNE USLUGI
ROZWIAZANIA AUTOMATYCZNE
ROZWIAZANIA NESTANDARDOWE
Kalkulator Cen
Otrzymaj natychmiastowa wycene wedlug minut i dodatkow
Program Lojalnosciowy
Zyskaj stale znizki
Znizka Edukacyjna
10% znizki dla studentow i edukatorow
Znizka dla organizacji non-profit
Znizki dla organizacji non-profit i NGO
Znizka Zielonej Inicjatywy
Znizki dla organizacji klimatycznych
Edukacja
Szybsze procesy badawcze · 10% znizki .edu
Administracja publiczna
Bezpieczna transkrypcja zgodna z wymogami
Prawo
Transkrypcje i zalaczniki gotowe do sadu
Medycyna
Transkrypcja zgodna z HIPAA
Dostawcy uslug jezykowych
Skaluj moce i chro marze
Organy scigania
Transkrypcje gotowe jako material dowodowy
Komunikacja Wewnetrzna
Zamien spotkania w przeszukiwalne notatki
Badania Rynku
Zamien sesje w cenne wnioski
Organizacje informacyjne
Transkrypcje gotowe do publikacji
Case studies
Historie sukcesu klientow
Partnerstwo
Integracje, resellerzy i afilianci
Centrum Zaufania
Przeglad bezpieczenstwa i zgodnosci
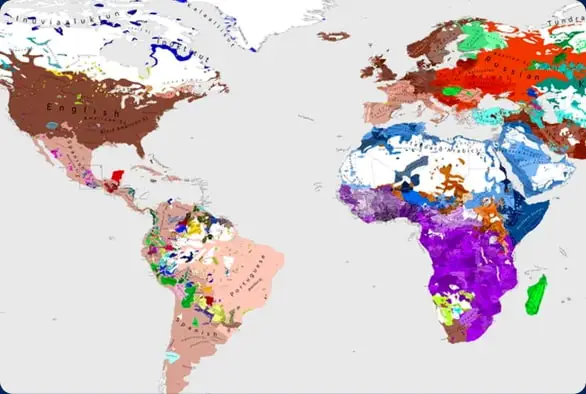
Nasze Jezyki
Obsluga ponad 140 jezykow
O nas
Nasza historia i misja
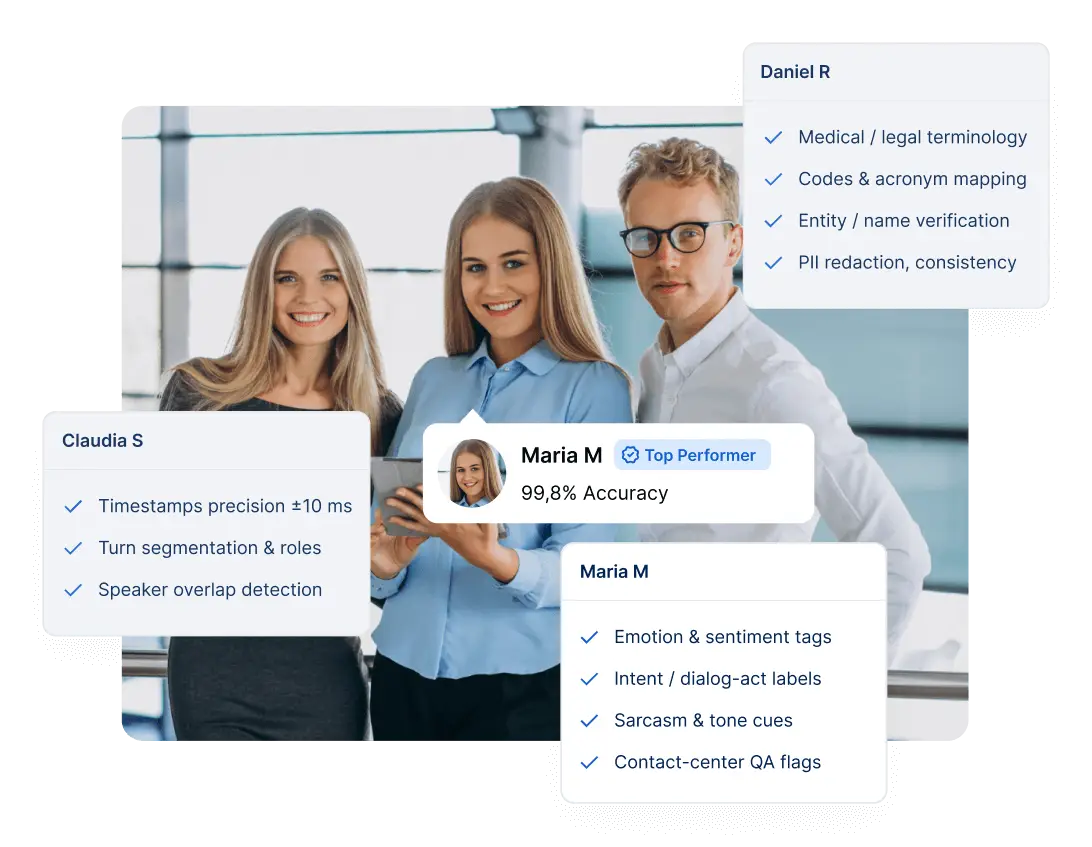
Nasz Zespol
Poznaj zespol stojacy za GoTranscript
Blog
Poradniki i analizy branzowe
Kariera
Otwarte role i kultura pracy
Rozwiazania Enterprise
Projekty wielkoskalowe, API i etykietowanie zbiorow danych
Skontaktuj sie ze sprzedaza
Porozmawiaj ze specjalista o cenach i rozwiazaniach
Umow Spotkanie
Umow rozmowe - potwierdzimy ja w ciagu 24 godzin
Wsparcie dla edukacji i kampusow
Zamowienia zakupu, warunki Net 30 i znizki .edu
Wsparcie Zamowien
Pomoc przy statusie zamowienia, zmianach lub rozliczeniach
Centrum Pomocy
Znajdz odpowiedzi i uzyskaj wsparcie 24/7
Zapytania Ogolne
Pytania dotyczace uslug, rozliczen lub bezpieczenstwa
Kariera
Sprawdz otwarte role i aplikuj.
-
 Transkrypcja
przez profesjonalnego transkrybenta i redaktora
Transkrypcja
przez profesjonalnego transkrybenta i redaktora
-
 Napisy (FCC/SDH)
przez profesjonalnego specjaliste od napisow
Napisy (FCC/SDH)
przez profesjonalnego specjaliste od napisow
-
 Redakcja i korekta transkrypcji
przez profesjonalnego redaktora
Redakcja i korekta transkrypcji
przez profesjonalnego redaktora
-
 Tlumaczenie (tekst/audio/obrazy)
przez profesjonalnego tlumacza
Tlumaczenie (tekst/audio/obrazy)
przez profesjonalnego tlumacza
-
 Napisy
przez profesjonalnego tworce napisow
Napisy
przez profesjonalnego tworce napisow
-
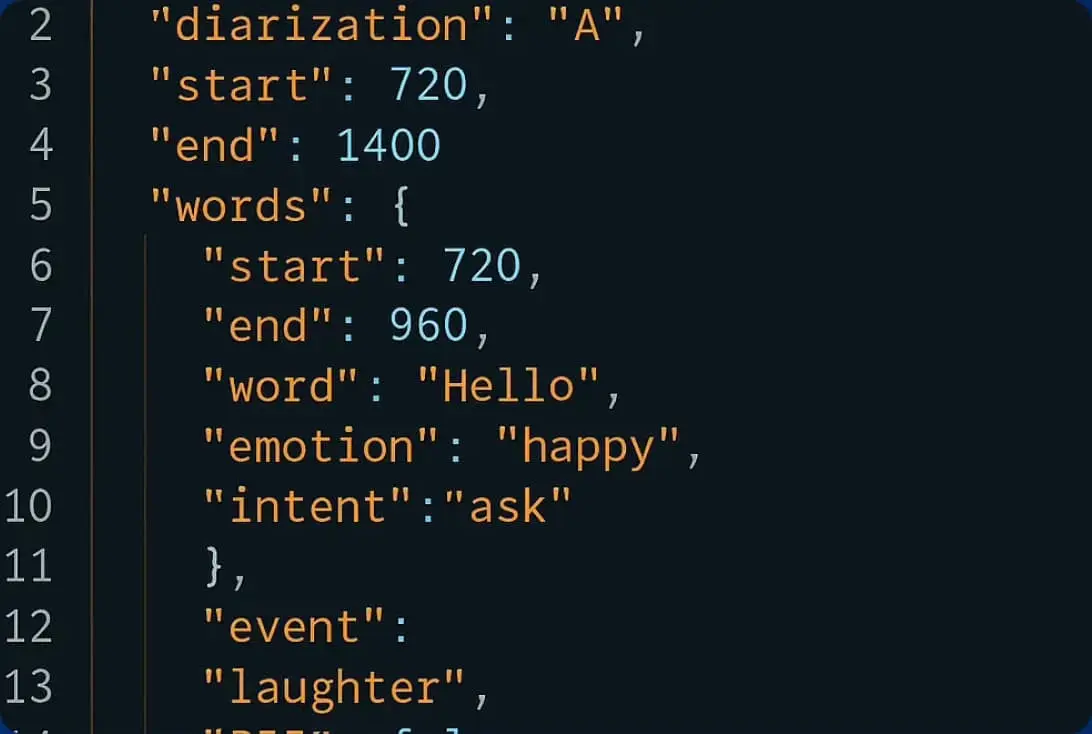
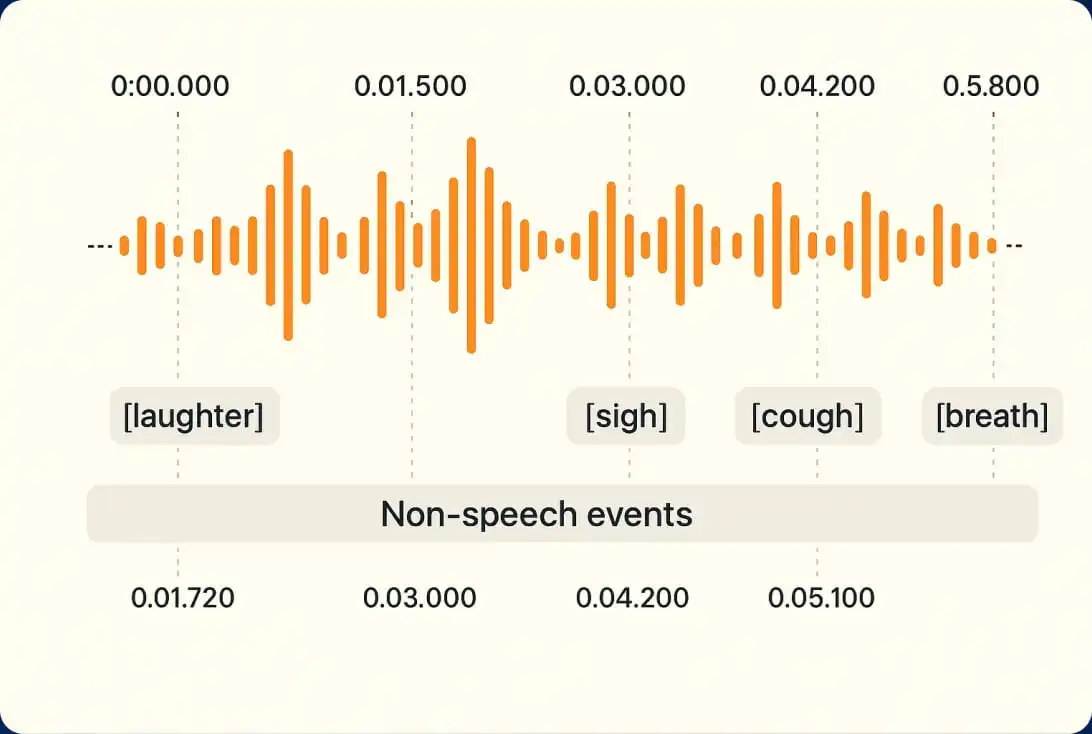
Transkrypcja AI (Automatyczna)
dla szybszej realizacji
-
 Audiodeskrypcja (AD)
przez profesjonalnego audiodeskryptora
Audiodeskrypcja (AD)
przez profesjonalnego audiodeskryptora