SERVICES PROFESSIONNELS
SOLUTIONS AUTOMATISEES
SOLUTIONS SUR MESURE
Calculateur de tarifs
Obtenez une estimation instantanee par minutes et options
Programme de fidelite
Beneficiez de remises continues
Remise education
10% de remise pour etudiants et enseignants
Remise associations
Remises pour les organisations a but non lucratif et les ONG
Remise initiative verte
Remises pour organisations climat
Education
Workflows de recherche plus rapides · 10% de remise .edu
Secteur public
Transcription securisee et conforme
Juridique
Transcriptions et pieces pretes pour le tribunal
Medical
Transcription conforme a la HIPAA
Prestataires de services linguistiques
Augmentez la capacite et protegez les marges
Forces de l'ordre
Transcriptions prêtes a servir de preuve
Communications internes
Transformez les reunions en notes consultables
Etudes de marche
Transformez les sessions en insights
Organisations d'information
Transcriptions prêtes a etre publiees
Etudes de cas
Histoires de reussite clients
Partenariat
Integrations, revendeurs et partenaires affilies
Centre de confiance
Apercu securite et conformite
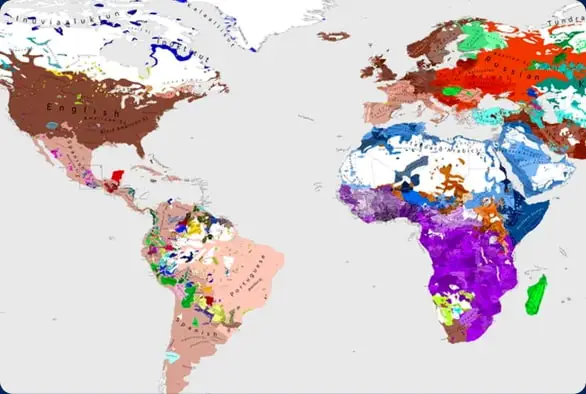
Nos langues
Couverture en plus de 140 langues
A propos
Notre histoire et mission
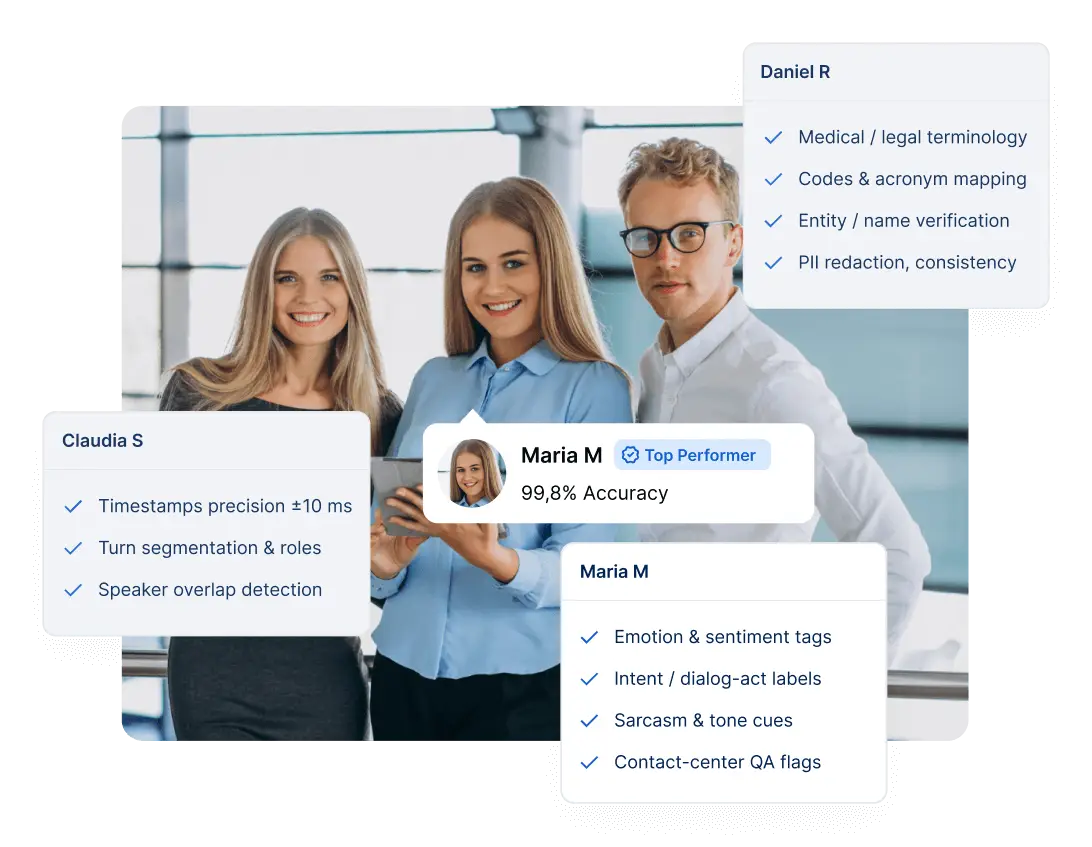
Notre equipe
Rencontrez les personnes derriere GoTranscript
Blog
Guides pratiques et perspectives du secteur
Carrieres
Postes ouverts et culture
Solutions entreprises
Projets a grand volume, API et annotation de jeux de donnees
Parler aux ventes
Parlez avec un specialiste des tarifs et solutions
Prendre rendez-vous
Planifiez un appel - nous le confirmerons sous 24 heures
Support education et campus
Bons de commande, conditions Net 30 et remises .edu
Support commandes
Aide pour statut de commande, changements ou facturation
Centre d'aide
Trouvez des reponses et obtenez de l'aide 24/7
Demandes generales
Questions sur les services, la facturation ou la securite
Carrieres
Decouvrez les postes ouverts et postulez.
-
 Transcription
par un transcripteur et editeur professionnel
Transcription
par un transcripteur et editeur professionnel
-
 Sous-titres (FCC/SDH)
par un professionnel du sous-titrage
Sous-titres (FCC/SDH)
par un professionnel du sous-titrage
-
 Edition et relecture de transcription
par un editeur professionnel
Edition et relecture de transcription
par un editeur professionnel
-
 Traduction (texte/audio/images)
par un traducteur professionnel
Traduction (texte/audio/images)
par un traducteur professionnel
-
 Sous-titres
par un sous-titreur professionnel
Sous-titres
par un sous-titreur professionnel
-
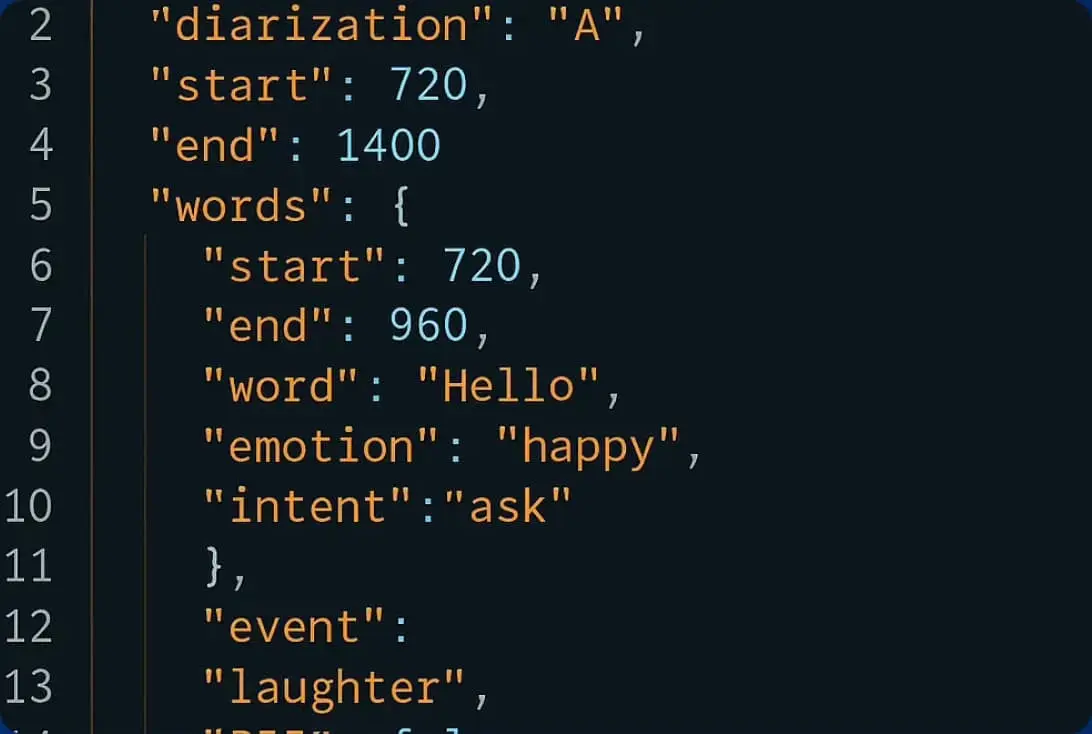
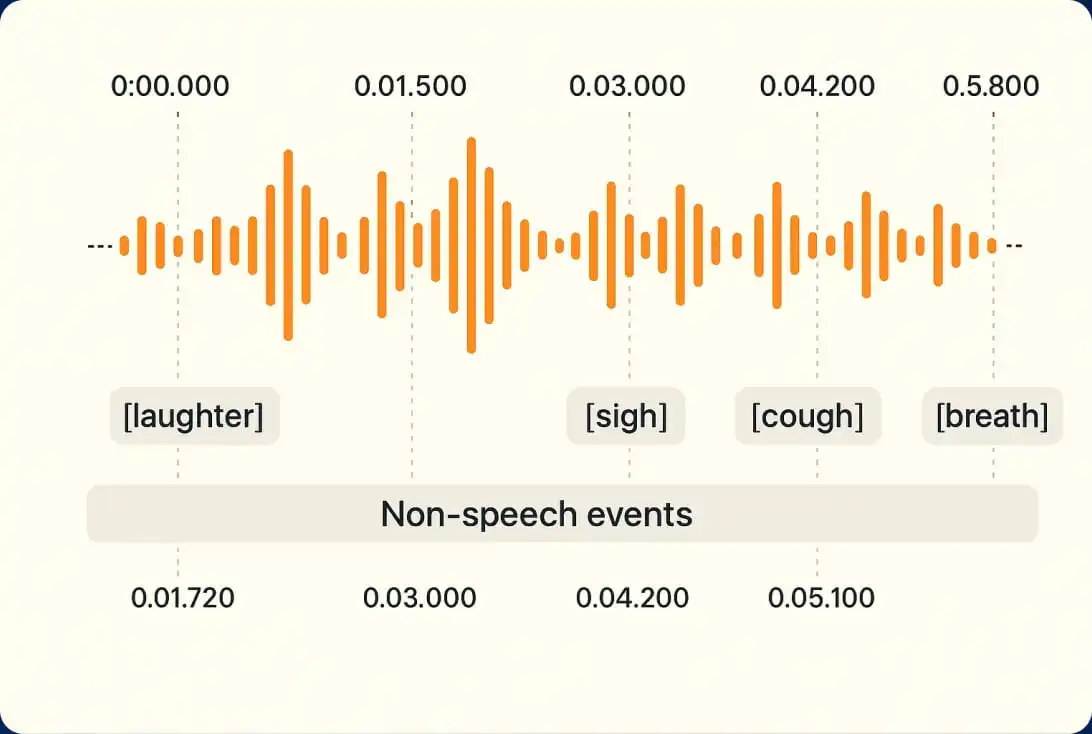
Transcription IA (automatisee)
pour un delai plus rapide
-
 Description video (AD)
par un descripteur professionnel
Description video (AD)
par un descripteur professionnel